Which LLM Should You Choose in 2026?
You're building an app that uses AI. You need to pick a model. And suddenly you're drowning in options: Claude, GPT-4o, Gemini, Llama, DeepSeek, Mistral - each with its own pricing, context limits, and tradeoffs.
This isn't an academic benchmark comparison. This is the guide I wish I had when I first started integrating LLMs into production apps - practical, opinionated, and focused on what actually matters for developers shipping real products.
Want to skip the reading and compare models interactively? Try the LLM Comparison Tool.
The Dimensions That Actually Matter
When choosing an LLM for your app, six things matter more than everything else:
- Pricing - How much per million tokens (input and output)? This is the single biggest cost lever in your AI app. A 10x price difference between models compounds fast at scale.
- Context window - How much text can the model process at once? Ranges from 128K to over 1M tokens. Critical for RAG, document processing, and complex multi-turn conversations.
- Quality - How good is the model at reasoning, following instructions, and producing correct output? Harder to measure, but you'll feel the difference quickly.
- Speed - Time to first token and tokens per second. Matters for real-time chat, streaming UIs, and user experience.
- Coding ability - If you're building developer tools, code generation apps, or using AI for coding tasks, this varies significantly between models.
- Vision - Can the model understand images? Essential for multimodal apps, OCR, and visual analysis.
The Models: Provider by Provider
Anthropic: Claude
Anthropic offers three tiers, all sharing a 200K token standard context window (up to 1M with extended context).
- Claude Opus 4 ($15/$75 per 1M tokens) - The most capable Claude model. Exceptional at complex reasoning, deep analysis, and agentic tasks that require sustained focus over many steps. It's expensive, but when you need the best reasoning, nothing else matches. Supports vision.
- Claude Sonnet 4 ($3/$15 per 1M tokens) - The sweet spot. Excellent at coding, strong reasoning, fast enough for production, and reasonably priced. This is the model I'd recommend for most production apps. If you're only going to try one Claude model, make it this one.
- Claude Haiku 3.5 ($0.80/$4 per 1M tokens) - The speed and cost champion. Great for classification, extraction, simple chat, and high-volume workloads where you need to keep costs down. Not ideal for complex reasoning.
OpenAI: GPT
OpenAI has the largest ecosystem and the most battle-tested APIs. Their model lineup has expanded significantly.
- GPT-4o ($2.50/$10 per 1M tokens) - OpenAI's flagship multimodal model. Good at everything, great at nothing in particular. Solid coding, solid reasoning, solid speed. The safe default if you're already in the OpenAI ecosystem. 128K context.
- GPT-4o mini ($0.15/$0.60 per 1M tokens) - Extremely cheap. Good enough for simple classification, extraction, and lightweight chat. One of the cheapest proprietary options available. 128K context.
- GPT-4.1 ($2/$8 per 1M tokens) - OpenAI's newest model, optimized for coding and instruction following. Massive 1M token context window and 32K max output. Strong choice for coding-heavy workloads and long-context tasks.
Google: Gemini
Google's Gemini models stand out for their massive context windows and competitive pricing.
- Gemini 2.5 Pro ($1.25/$10 per 1M tokens) - 1M token context window with strong reasoning capabilities. Great for research, document analysis, and any task that benefits from processing massive amounts of text at once. Competitive pricing for what you get.
- Gemini 2.5 Flash ($0.15/$0.60 per 1M tokens) - Same 1M context window at GPT-4o mini pricing. Excellent for high-volume workloads that need large context but don't require top-tier reasoning.
Open Source / Open Weight
For teams that need to self-host, avoid vendor lock-in, or keep data on-premises, open models have become genuinely competitive.
- Llama 4 Maverick (Free / self-hosted) - Meta's latest. 1M context window, vision support, and genuinely competitive quality. The obvious choice if you want to self-host. Active community and wide infrastructure support (Ollama, vLLM, Together AI, etc.).
- DeepSeek V3 ($0.27/$1.10 per 1M tokens) - Surprisingly strong coding model at a fraction of the price. Open weights. 131K context. No vision support. If your use case is primarily code generation and you're cost-sensitive, this is worth testing.
- Mistral Large ($2/$6 per 1M tokens) - EU-based provider with strong multilingual support. Good choice for European teams with data sovereignty requirements. Solid reasoning and function calling. 128K context.
Quick Comparison Table
| Model | Input | Output | Context | Speed | Vision |
|---|---|---|---|---|---|
| Claude Opus 4 | $15 | $75 | 200K | Slow | Yes |
| Claude Sonnet 4 | $3 | $15 | 200K | Medium | Yes |
| Claude Haiku 3.5 | $0.80 | $4 | 200K | Fast | Yes |
| GPT-4o | $2.50 | $10 | 128K | Medium | Yes |
| GPT-4o mini | $0.15 | $0.60 | 128K | Fast | Yes |
| GPT-4.1 | $2 | $8 | 1M | Medium | Yes |
| Gemini 2.5 Pro | $1.25 | $10 | 1M | Medium | Yes |
| Gemini 2.5 Flash | $0.15 | $0.60 | 1M | Fast | Yes |
| Llama 4 Maverick | Free | Free | 1M | Medium | Yes |
| DeepSeek V3 | $0.27 | $1.10 | 131K | Medium | No |
| Mistral Large | $2 | $6 | 128K | Medium | No |
Prices are per 1M tokens. "Free" means open weights - you pay only for infrastructure when self-hosting.

Which Model for Your Use Case?

Building a chatbot or customer support app?
Start with Claude Sonnet 4 or GPT-4o. Both offer a strong balance of quality, speed, and price for conversational AI. If costs are a concern, route simple queries to Haiku 3.5 or GPT-4o mini and escalate complex ones to the bigger model.
Need strong coding assistance?
Claude Sonnet 4 and GPT-4.1 are the top choices for code generation. Sonnet excels at understanding complex codebases, while GPT-4.1 is optimized for instruction following in coding tasks. DeepSeek V3 is a dark horse - surprisingly strong at coding for a fraction of the price.
Processing long documents?
Gemini 2.5 Pro is the clear winner with its 1M token context window and competitive pricing. You can feed it entire codebases, legal documents, or research papers. GPT-4.1 and Llama 4 Maverick also offer 1M context.
On a tight budget?
GPT-4o mini and Gemini 2.5 Flash are both $0.15/$0.60 per 1M tokens - nearly identical pricing. Gemini Flash wins on context window (1M vs 128K). For self-hosting, Llama 4 Maverick is free (you only pay for compute).
Need complex reasoning or analysis?
Claude Opus 4 is the strongest reasoner available. It's expensive, but for tasks that require deep analysis, multi-step reasoning, or agentic workflows, the quality difference justifies the cost. Use it surgically for hard tasks, not for every request.
Data sovereignty or self-hosting requirements?
Llama 4 Maverick for self-hosting with maximum control. Mistral Large if you want an EU-based API provider. DeepSeek V3 has open weights but the API runs from China, so self-hosting is the way to go for data-sensitive use cases.
My Recommendation
If I had to pick one model for a new production app today, it'd be Claude Sonnet 4. It's the best all-rounder: strong coding, solid reasoning, good speed, 200K context, vision support, and reasonable pricing at $3/$15 per million tokens. It pairs naturally with the stack I recommend for AI apps.
For production, I'd pair it with a cheaper model (Haiku 3.5 or GPT-4o mini) for simple tasks and route only complex queries to Sonnet. This pattern - a fast/cheap model for simple tasks + a capable model for hard tasks - is the most cost-effective architecture for AI apps in 2026.
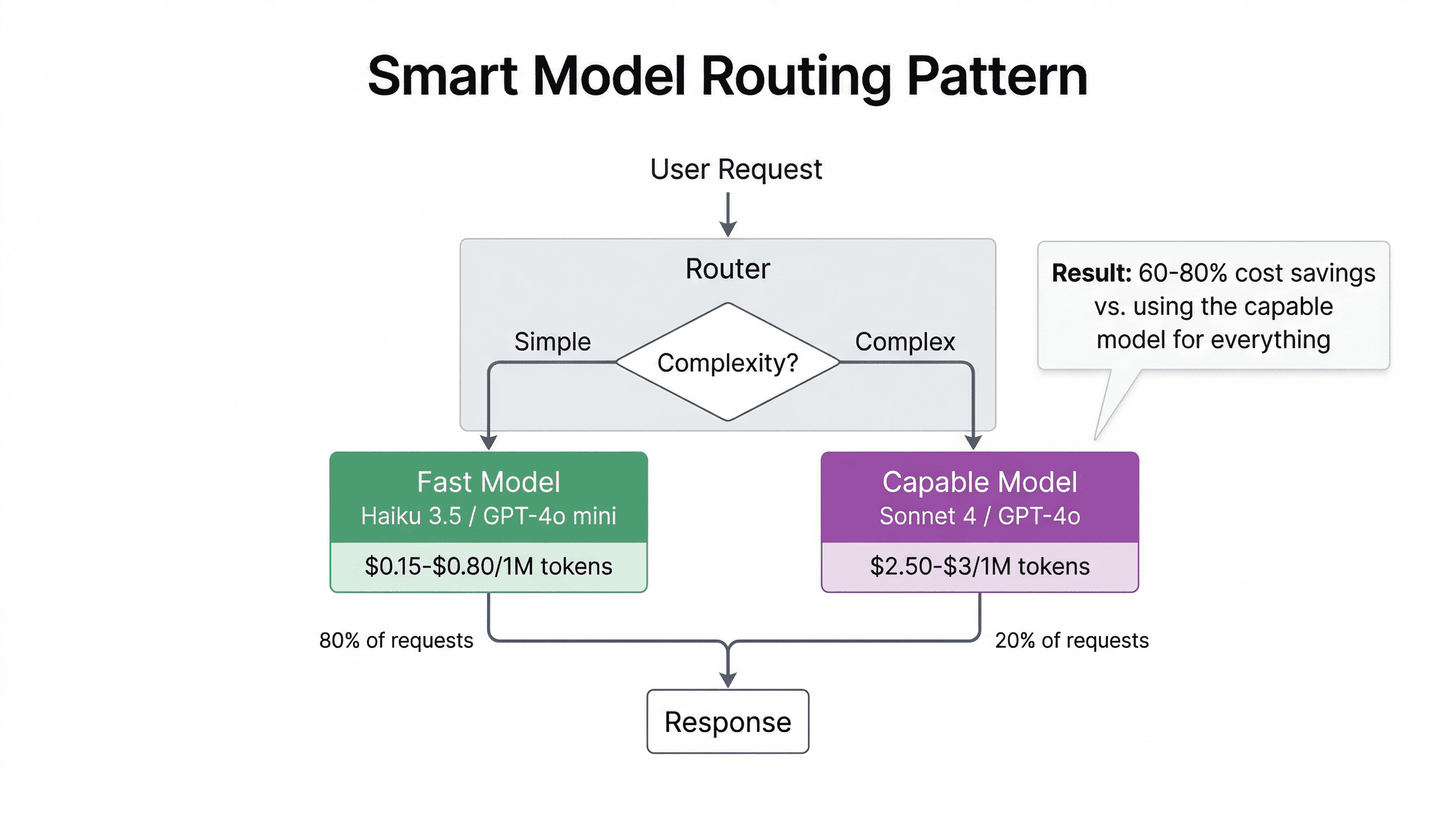
But don't take my word for it blindly. Test the top 2-3 contenders against your actual prompts and data. A model that benchmarks well might not work best for your specific use case.
Try It Yourself
I built an interactive LLM comparison tool where you can filter by use case, sort by pricing or context window, and compare up to 3 models side by side. Bookmark it for the next time you need to pick a model.
Related Reading
- How LLMs Actually Work: A Developer's Guide - Understand what's happening under the hood
- The Stack I'd Use to Build Any AI App in 2026 - The full tech stack that pairs with these models
- Inside Every AI Agent: Memory, Tools, and the System Prompt - How agents use these models in practice